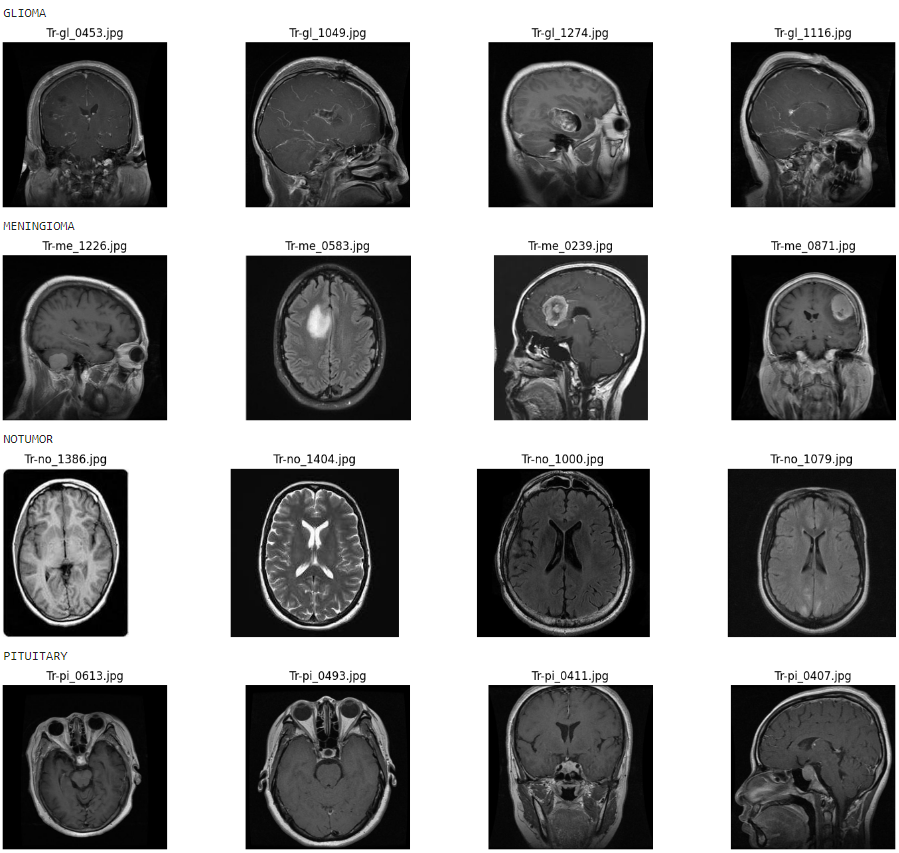
Brain Tumor Detection Model
This project involves developing a deep learning model to automatically detect brain tumors using MRI images. The model is designed to classify images into four categories: glioma tumor, meningioma tumor, no tumor, and pituitary tumor.
Data Processing: The images are first prepared by resizing them and converting them into a format suitable for the model. The data is split into a training set, used to train the model, and a validation set, used to test the model's performance.
Model Architecture: A pre-trained ResNet-50, a powerful image recognition model, is used and fine-tuned for this specific task. The model has been adapted to classify brain MRI images into the four categories mentioned above.
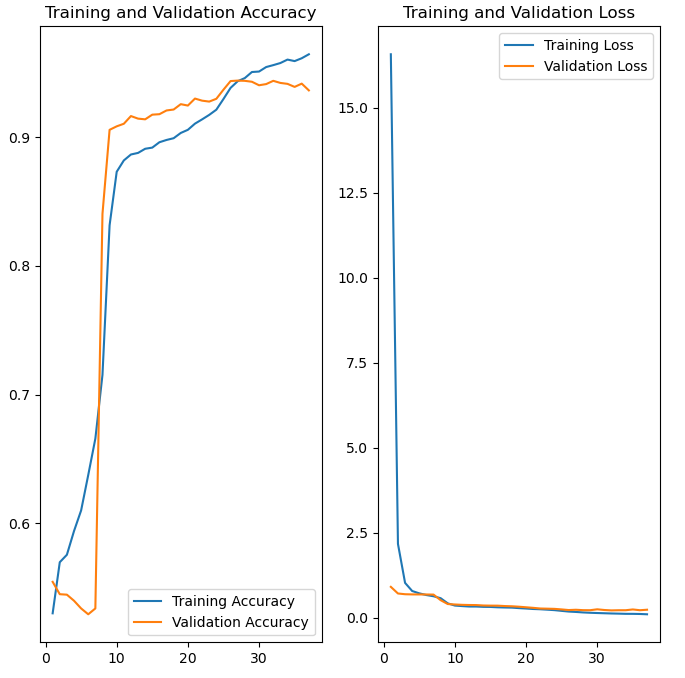
Training: The model is trained on a dataset of labeled MRI images, where it learns to identify different types of brain tumors. During training, the model’s accuracy and loss (error) are tracked to ensure that it’s improving over time.
Evaluation: After training, the model is evaluated using new, unseen images. A confusion matrix is used to assess how well the model distinguishes between the different tumor types. This helps to identify which types of tumors are being accurately classified and which are more challenging for the model.
Goal: The ultimate goal of the project is to create a reliable, automated tool that can assist doctors in detecting brain tumors early, potentially improving patient outcomes by providing faster and more accurate diagnoses.
This project showcases how artificial intelligence can be applied in the medical field to enhance diagnostic accuracy, particularly in complex areas like tumor detection.
View Code